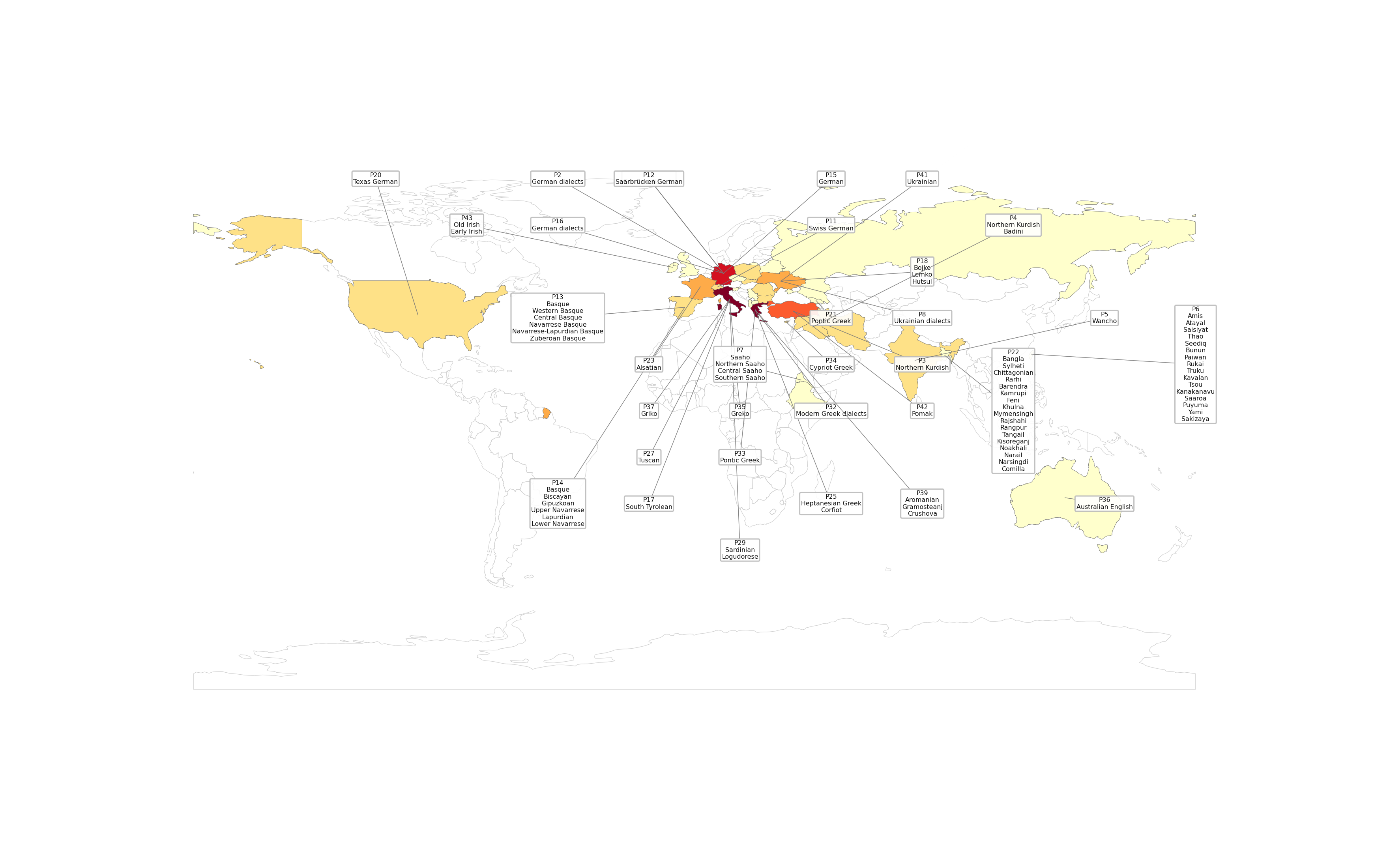
List of Accepted Papers
Beyond Accuracy: Analyzing Dialect Confusion in Automatic Speech-Based Dialect Classification
Lea Fischbach, Alfred Lameli and Lucie Flek
FLEURS-Kobani: Extending FLEURS dataset for Northern Kurdish
Daban Q. Jaff and Mohammad Mohammadamini
Exploring the reusability of Northern Kurdish resources for Badini speech recognition
Mohammad Mohammadamini, Aveen Jalal Mohammed, Barzan Hussein Mohammed, Dezheen H. Abdulazeez, Imad Saeed Sadeeq, Dilgash Mohammed Salih, Amera Ismail Melhum and Abuobaida Abdullah Dheyab
Wancho Dialectometry: Community-created data and the Living Dictionaries project
Kellen Parker van Dam
Dialectometry and Evaluation of the ePark Corpus for Low-Resource Formosan Language Dialects
Henry Gagnier
Beyond the National Standard: Multi-Dialectal NLP and the "No Dialect Left Behind" Framework for the Saaho Language
Jama Musse Jama
A Dialectal Corpus for Ukrainian: Collection, Classification, and Standardization
Yuliia Frund and Sina Ahmadi
German Dialects across Situations, Generations, and Regions: The REDE Corpus as an Oral Resource for NLP
Hanna Fischer and Alfred Lameli
Can LLM Agents Identify Spoken Dialects like a Linguist?
Tobias Bystrich, Lukas Hamm, Maria Hassan Akhter, Lea Fischbach, Lucie Flek and Akbar Karimi
Saar-Voice: A Multi-Speaker Saarbrücken Dialect Speech Corpus
Lena Sophie Oberkircher, Jesujoba Alabi, Dietrich Klakow and Jürgen Trouvain
A Catalog of Basque Dialectal Resources: Online Collections and Standard-to-Dialectal Adaptations
Jaione Bengoetxea, Itziar Gonzalez-Dios and Rodrigo Agerri
Phonologically-aware Automatic Speech Recognition Evaluation of Low-Resource Languages: The Case of Basque Dialects
Christoforos Souganidis, Asier Herranz, Ibon Saratxaga, Eva Navas and Inma Hernaez
WoVis: Interactive Visualization of Word Embeddings for Semantic Change in Historical and Dialectal Language Resources
Filip Miletić, Maximilian Henkel, Rene Cutura, Sophie Sadler, Quynh Quang Ngo, Michael Sedlmair and Sabine Schulte im Walde
Speaker Normalization via Voice Conversion Reveals a Human-Machine Dissociation in Dialect Classification
Caroline Kleen, Lea Fischbach, Akbar Karimi, Lucie Flek and Alfred Lameli
South Tyrolean Dialect-to-Standard Speech Translation
Greta H. Franzini and Luca Ducceschi
TransVar – the Corpus for Variation and Change Study of the Historical Transcarpathian lects
Ilia Afanasev
The Generator-Eraser Paradox: Community Guidelines for Responsible LLM-Assisted Dialect Resource Creation
Wajdi Zaghouani
The Texas German Dialect Project Corpus as a Diachronic Resource for Investigating Language Contact
Thomas Schmidt, Margaret M. Blevins, Hans C. Boas and Glenn Gilbert
Pontic Greek in the Caucasus: an online corpus
Svetlana Berikashvili and Stavros Skopeteas
Meaning Over Morphology: A Multi-Metric Benchmark of LLMs for Bangla Dialect Translation
Soumik Deb Niloy, Subhey Sadi Rahman, Mahbub E Sobhani, Md. Golam Rabiul Alam, Farig Yousuf Sadeque and Md. Rezuwan Hassan
Sociolinguistic aspects of crowdsourcing for a vocal corpus of Alsatian
Pascale Erhart, Lucile Hamm, Sam Bigeard, Carole Werner, Malek Yaich and Slim Ouni
HeptaTAX: A Neuro-Symbolic Pipeline and Benchmark for Classifying 16th-Century Heptanesian Notarial Acts
Stergios Chatzikyriakidis, Eleni Karantzola and Vasiliki Makri
Towards Semantic Access and Interoperability in Digital Dialectal Atlases. A Case Study
Paola Marongiu and Simonetta Montemagni
A Bolu: A Structured Dataset for the Computational Analysis of Sardinian Improvisational Poetry
Silvio Calderaro and Johanna Monti
A CLDF-Compliant Lexical Database for Modern Greek Dialects: Resource Design and Dialectometric Analysis
Stavros Bompolas, Natalia Chousou-Polydouri, Manuela Genitsaridi, Danae Karatzanou, Georgios Kostopoulos, Elena Anagnostopoulou and Dimitra Melissaropoulou
A Speech Resource for the Pontic Greek Dialect: Transcription Choices and Baseline ASR Evaluation
Rodanna Konstantinidou, Chara Tsoukala, Vivian Stamou, Voula Giouli and Stella Markantonatou
First Steps in ASR for Cypriot Greek: Challenges and Insights
Vivian Stamou, Spyros Armostis, Antigoni Klimi, Georgios Paraskevopoulos, Vassilis Katsouros and Antonios Anastasopoulos
Evaluating Cross-Dialect Syntactic Variation: a Theory-Driven Web Resource
Emanuela Li Destri, Marco Longhin, Gaia Sorge, Sofia Ferroni, Giovanni Battista Matteazzi, Andrea Artioli, Lorenzo Carletti, Federico Motta, Giuseppe Longobardi and Cristina Guardiano
MD_NLP: Reconstructing an Australian English Heritage Dialect Corpus from the Mitchell–Delbridge Recordings through LLM-Assisted Speaker Attribution
Steven Coats
Structural Divergence under Shared Language-Level Specification: Griko in Universal Dependencies
Stavros Bompolas, Emanuela Pinna, Josep Quer, Marika Lekakou and Stella Markantonatou
Systematic Normalization of Spoken Mixed-Language, Mixed-Dialect Data
Margaret Blevins
Digital Preservation of Aromanian Through Knowledge Management and Automatic Speech Recognition Evaluation
Marija Pendevska and Hristina Nastevska
A Novel Typology of Mutually Intelligible Words: The Case of Slavic Languages
Edward Klyshinsky and Yulia Badryzlova
Transfer Learning for an Endangered Slavic Variety: Dependency Parsing in Pomak Across Contact-Shaped Dialects
Sercan Karakas
Challenges in the Detection of Dialect for Historical Languages; the Case of Old Irish Text Resources
Adrian Doyle
No papers match your search.